//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*blockDim.x+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>0; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
intmain(){ unsignedint N = 1000000; size_t bytes = N * sizeof(float); int blockSize = THREAD_PER_BLOCK; // 256线程/block int elementsPerBlock = blockSize * NUM_PER_THREAD; // 256 * 8 = 2048元素/block int gridSize = (N + elementsPerBlock - 1) / elementsPerBlock; //确定网格尺寸,能够处理所有N个元素
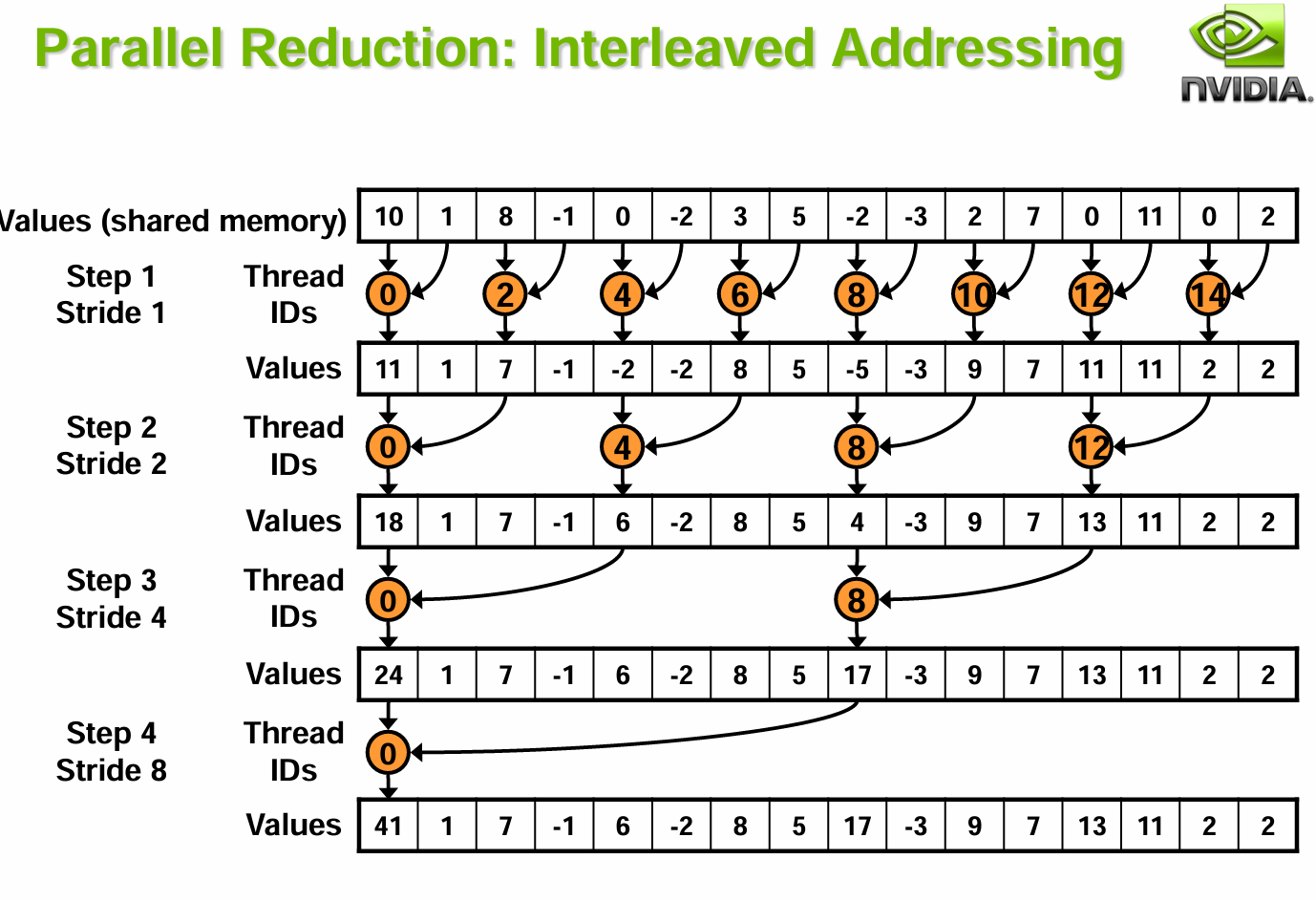
__global__ voidreduce0(int *g_idata, int *g_odata){ extern __shared__ int sdata[]; // each thread loads one element from global to shared mem unsignedint tid = threadIdx.x; unsignedint i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = g_idata[i]; __syncthreads(); // do reduction in shared mem for(unsignedint s=1; s < blockDim.x; s *= 2) { if (tid % (2*s) == 0) { sdata[tid] += sdata[tid + s]; } __syncthreads(); } // write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = sdata[0]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*blockDim.x+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i]; __syncthreads();
// do reduction in shared mem for(unsignedint s=1; s<blockDim.x; s*=2){ int index = 2*s*tid; if(index < blockDim.x){//不同线程束执行不同 sdata[index]+=sdata[index+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*blockDim.x+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>0; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; //核心,每个block处理两个block unsignedint tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>0; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; __syncthreads();
// do reduction in shared mem for(unsignedint s=blockDim.x/2; s>32; s>>=1){ if(tid < s){ sdata[tid]+=sdata[tid+s]; } __syncthreads(); } // write result for this block to global mem if(tid<32)warpReduce(sdata,tid); if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
//each thread loads one element from global memory to shared mem unsignedint i=blockIdx.x*(blockDim.x*2)+threadIdx.x; unsignedint tid=threadIdx.x; sdata[tid]=d_in[i] + d_in[i+blockDim.x]; __syncthreads();
// do reduction in shared mem if(blockSize>=512){ if(tid<256){ sdata[tid]+=sdata[tid+256]; } __syncthreads(); } if(blockSize>=256){ if(tid<128){ sdata[tid]+=sdata[tid+128]; } __syncthreads(); } if(blockSize>=128){ if(tid<64){ sdata[tid]+=sdata[tid+64]; } __syncthreads(); } // write result for this block to global mem if(tid<32)warpReduce<blockSize>(sdata,tid); if(tid==0)d_out[blockIdx.x]=sdata[tid]; }
// each thread loads NUM_PER_THREAD element from global to shared mem unsignedint tid = threadIdx.x; unsignedint i = blockIdx.x * (blockSize * NUM_PER_THREAD) + threadIdx.x;
// do reduction in shared mem if (blockSize >= 512) { if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads(); } if (blockSize >= 256) { if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads(); } if (blockSize >= 128) { if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads(); } if (tid < 32) warpReduce<blockSize>(sdata, tid); // write result for this block to global mem if (tid == 0) d_out[blockIdx.x] = sdata[0]; }
template <unsignedint blockSize> __device__ __forceinline__ floatwarpReduceSum(float sum){ if (blockSize >= 32)sum += __shfl_down_sync(0xffffffff, sum, 16); // 0-16, 1-17, 2-18, etc. if (blockSize >= 16)sum += __shfl_down_sync(0xffffffff, sum, 8);// 0-8, 1-9, 2-10, etc. if (blockSize >= 8)sum += __shfl_down_sync(0xffffffff, sum, 4);// 0-4, 1-5, 2-6, etc. if (blockSize >= 4)sum += __shfl_down_sync(0xffffffff, sum, 2);// 0-2, 1-3, 4-6, 5-7, etc. if (blockSize >= 2)sum += __shfl_down_sync(0xffffffff, sum, 1);// 0-1, 2-3, 4-5, etc. return sum; } template <unsignedint blockSize, int NUM_PER_THREAD> __global__ voidreduce7(float *d_in,float *d_out, unsignedint n){ float sum = 0;
// each thread loads one element from global to shared mem unsignedint tid = threadIdx.x;
#pragma unroll //线程级局部规约 for(int iter=0; iter<NUM_PER_THREAD; iter++){ sum += d_in[i+iter*blockSize]; } // Shared mem for partial sums (one per warp in the block) static __shared__ float warpLevelSums[WARP_SIZE]; constint laneId = threadIdx.x % WARP_SIZE; constint warpId = threadIdx.x / WARP_SIZE;
sum = warpReduceSum<blockSize>(sum);
if(laneId == 0 )warpLevelSums[warpId] = sum; __syncthreads(); // read from shared memory only if that warp existed sum = (threadIdx.x < blockDim.x / WARP_SIZE) ? warpLevelSums[laneId] : 0; // Final reduce using first warp if (warpId == 0) sum = warpReduceSum<blockSize/WARP_SIZE>(sum); // write result for this block to global mem if (tid == 0) d_out[blockIdx.x] = sum; } reduce7<THREAD_PER_BLOCK, NUM_PER_THREAD><<<Grid,Block>>>(d_a, d_out, N);