转载、参考: https://zhuanlan.zhihu.com/p/1910636263666610461
计算量推导
矩阵乘法:
$C = \alpha AB + \beta C$
$A$ 形状为 $M \times K$ ,$B$ 形状为 $ K \times N $ ,$C$ 形状为 $M \times N$。
矩阵 $A$($M \times K$)与 $B$($K \times N$)相乘,得到 $C$($M \times N$)。
每个 $C_{i,j}$ 的计算:
$$
C_{i,j} = \sum_{k=1}^{K} A_{i,k} B_{k,j}
$$
每个元素需要 $K$ 次乘法和 $K-1$ 次加法,计算$AB$需要$(2K-1)MN$次浮点计算,缩放$MN$和$C$各需要$MN$次计算,最后两个矩阵相加需要$MN$次计算,总计算为$(2K-1)MN+MN+MN+MN = (2K+2)MN$次计算,约为
navie
每个 thread 负责 C 中一个元素的计算
1 | __global__ void GEMM(float* A,float*B,float*C,const int M,const int N,const int K){ |
问题:全局显存访问2MNK,全局带宽占用受限制
思路:转移到shared_memory
分块计算
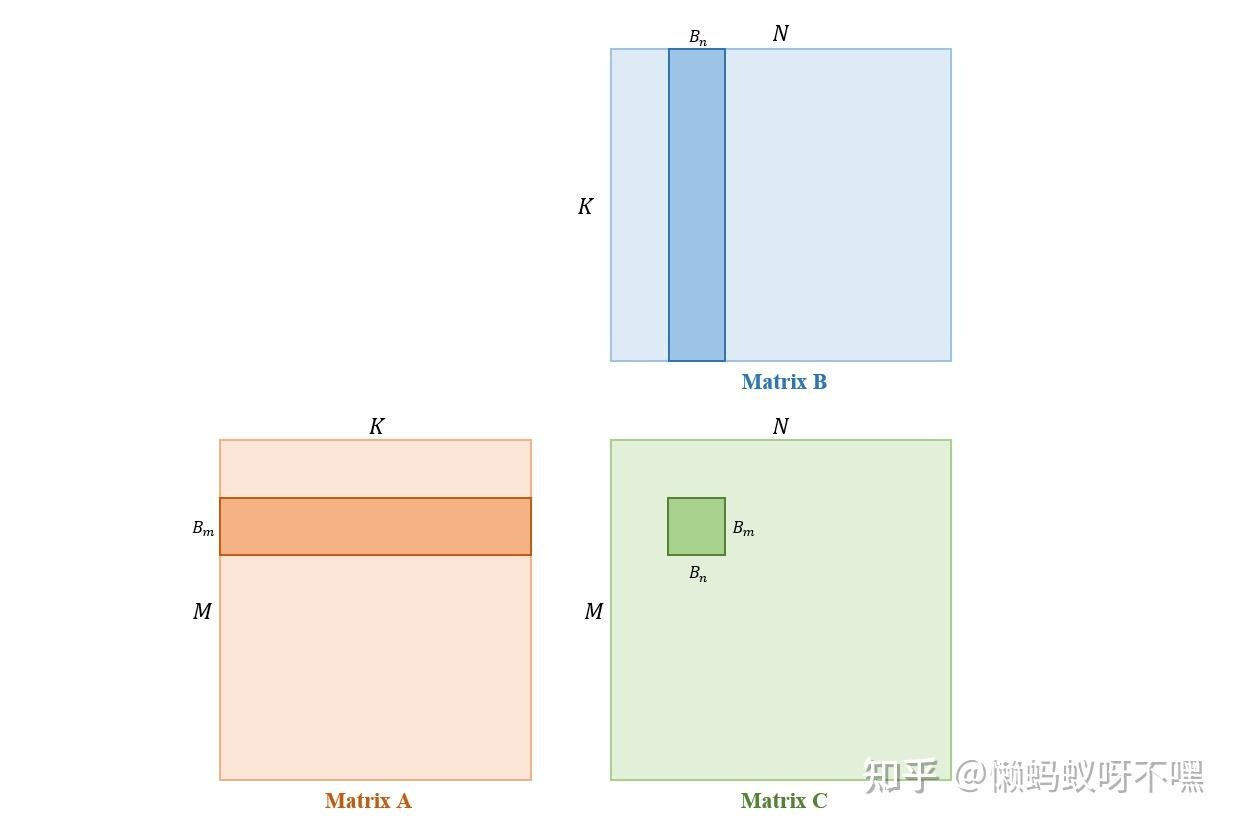
分块计算以后,将Bm和Bn计算放置到shared-memory中可以有效减少全局内存访问次数,因为在块内复用了一部分
但是K通常很大,可能无法放下,所以说需要在K的维度上拆分: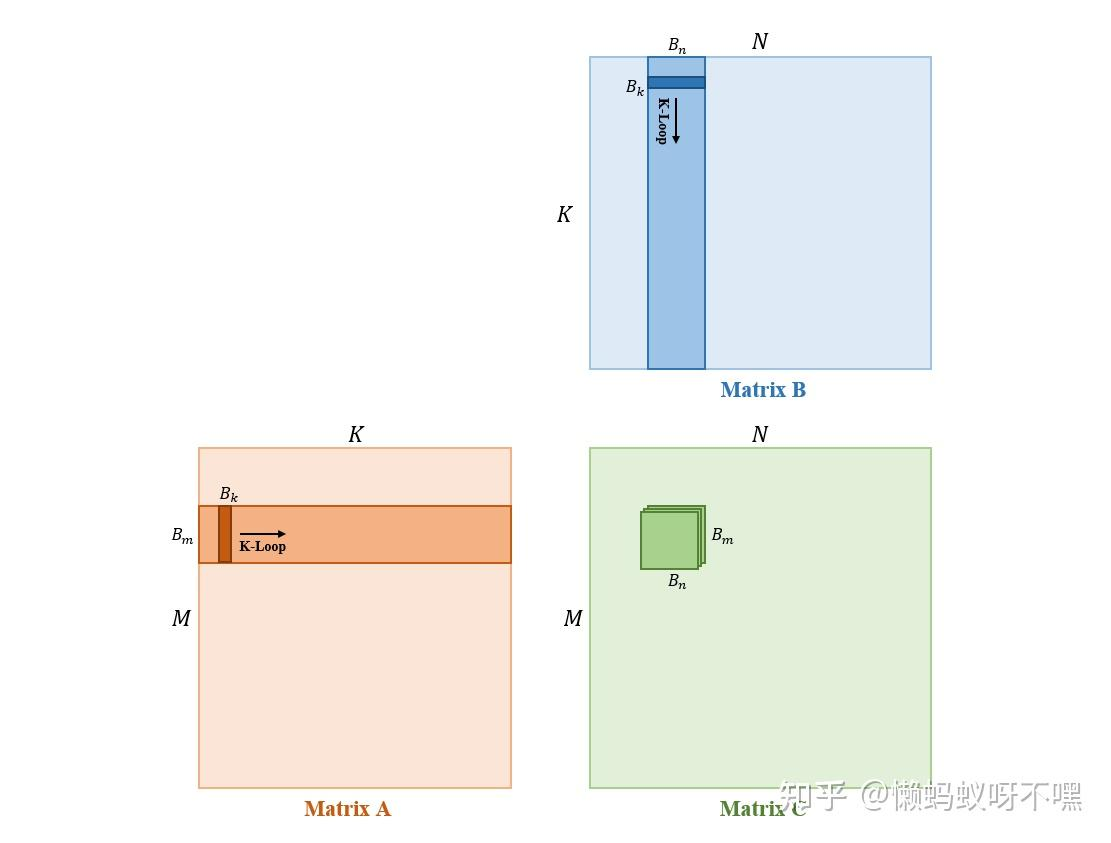
bk \bm\bn的数据会影响性能,文章根据计算量、访存量进行了推算,选定bk=8 bm=bn=128
流程:
- 申请 shared memory 空间,用于存储每次循环中矩阵 和矩阵 参与计算的 tile,变量名为
As和Bs。- 计算每个 thread 负责的矩阵 中的元素个数,定义相同大小的寄存器数组
Ct,用于存储累加结果。- K-Loop 循环,循环步长为 ,循环体包括:
1. 从 global memory 上的矩阵 中读取参与计算的 tileA,存入As;
- 从 global memory 上的矩阵 中读取参与计算的 tileB,存入
Bs;- 线程块内同步;
- 计算
As与Bs的矩阵相乘结果,累加存入Ct;- 线程块内同步;
- 循环完成后,将
Ct结果写入 global memory 上的矩阵 中对应位置。



