Tiered Memory Management Beyond Hotness
Jinshu Liu Hamid Hadian Hanchen Xu Huaicheng Li Virginia Tech
Virginia 这个MoatLab对CXL内存的研究很深入,之前的Pond(ASPLOS `23)、Melody(ASPLOS`25)都出自这个实验室
1.Introduction
Hot data is not always performance-critical and can reside in the slow-tier without degrading performance .
Latency mitigation techniques, such as memory-level parallelism (MLP), obscure the true cost of memory accesses
1.先前的工作通过启发式或者内存访问成本间接的反应MLP的影响,但是仍然缺少准确的MLP建模和指标。
2.现有的内存分层方法具有难以轻量化和不准确的特点。尤其是一开始先放置本地内存的方法本身就是次优的,并且激进的迁移策略会导致过分的迁移。
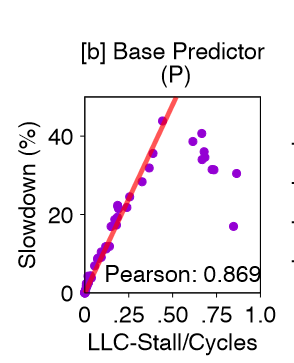
所以作者就定义了一个MLP影响的指标,AOL,并且用来辅助放置决策和迁移决策。
Propose Amortized Offcore Latency (AOL), a novel performance metric that accurately quantifies the performance impact of memory accesses by integrating memory latency and MLP.
放置决策策略SOAR基于AOL进行排序,然后以此决定放置。ALTO依靠AOL来进行页面提升的过滤,可以与TPP等策略进行结合。
2.Background and Motivation
MLP反映等待内存控制器实现的内存请求数量。
high-MLP access patterns: array traversals。
low MLP:pointer-chasing with depedent requests
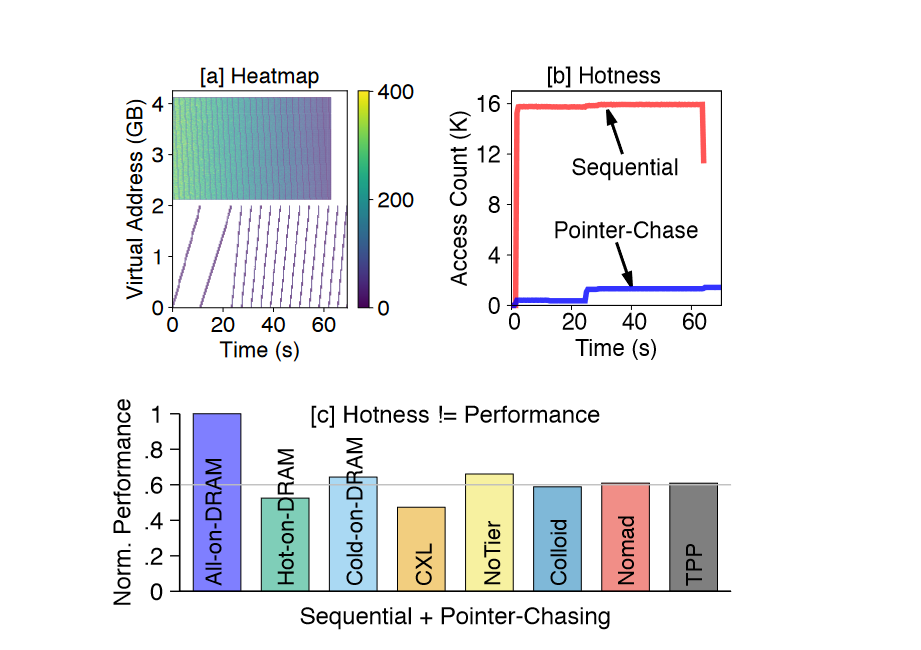
把两个类型的访存一起跑,然后不同的分层策略依照不同的策略跑了测性能,发现把数组访问的放到快速层,反而会使性能降低。
3.Memory Performance Prediction
Relating Slow-tier Performance to CPU Stalls
离线分析
Performance degradation on the slow-tier is predominantly caused by increased CPU stalls due to LLC misses, which we refer to as LLC-Stalls
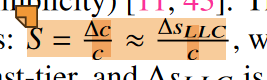
强调区分LLC-miss和LLC-Stall 慢速层单次miss造成的延迟更长,假设相同的miss,慢速层也会有更长的LLC-Stall.
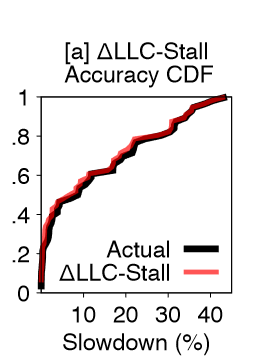
论文中讲到基于LLC-Stall来预测减速的误差低于4%,开源以后可以预测一下基于LLC-Miss的(考虑预取器的影响)。
LLC-Stalls for Performance Prediction
在线预测
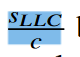
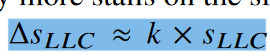
发现快速层发生CPUStall的在慢速层也会发生。
所以用P= SLLC/c来预测慢速层的减速。
AOL for Accurate Prediction
进一步研究发现,P在低MLP的场景下准确,但是在高MLP的场景下并不准确、主要是忽略了MLP的影响,高MLP会减少长延迟的影响。
随着延迟的增加,MLP的延迟掩盖受益会降低。
因此定义了AOL: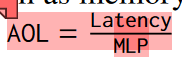

| 指标 | 事件 | 含义 |
|---|---|---|
| 𝑠𝐿𝐿𝐶 | CYCLE ACTIVITY.STALLS L3 MISS | L3 Miss时导致的Stall |
| c | CPU_CLK_UNHALTED.THREAD | 非Halt下的时钟周期数 |
| A1 | OFFCORE_REQUESTS_OUTSTANDING.CYCLES_WITH_DATA_RD | L2 Miss 后、请求完成前,这些内存读取请求在 SQ 中等待的周期数 换言之,每个时钟周期检查是否存在至少一个load请求,有就加1 |
| A2 | OFFCORE_REQUESTS_OUTSTANDING.DEMAND_DATA_RD | L2 miss 后,每个周期有多少个未完成的 Demand Load 请求在SQ中等待,即:请求堆积的深度/压力。 |
| A3 | OFFCORE REQUESTS.DEMAND DATA RD | L2 miss 后,被发往 uncore 的 load 请求的次数。 |
延迟计算运用到了排队论中的Little`s法则:
平均在系统中的项数 L = 到达率 λ × 平均响应时间 W结合事件:
- L = 某个时间段内,在 uncore 正在等待完成的请求数(单位:个),即 “每周期 outstanding 的请求数”
- λ = 请求到达速率(单位:请求/周期)≈ 总请求数 / 总周期数
- W = 每个请求在系统中停留的时间(单位:周期)→ 平均延迟
W = L / λ = 平均 outstanding 请求数 / 到达速率
根据排队理论,计算得1。
MLP是平均每个周期内多少个inflight内存请求,衡量内存访问的并行度。
A2代表总的堆积请求数,总的堆积请求数(A2)除以总的堆积周期数(A1),得到每个周期的平均inflight请求数。
1、2代入的AOL。 延迟除以并行请求,得到了一个并行请求下单个请求的延迟影响。

然后作者定义了减速模型:S= P x K.
k = f(AOL)的函数是用S/P与AOL进行分析,反向呈现出特定的渐进双曲线,反推出了其数学模型。
关于a和b,与硬件相关而与工作负载无关的常数,两个特定的场景(指针追踪、数组访问)能够推出(估计待定系数法)
分析: AOL增加时(MLP减小或者Latency增大),K趋近到上界1,S接近P,预测由LLC.stall/c决定。相反(MLP增大或者Latency减少),K趋近下界0,S减小
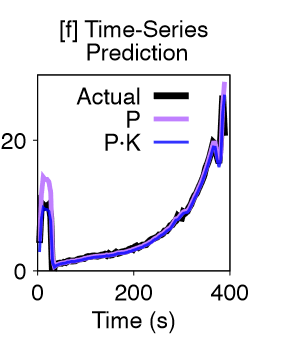
有了预测模型以后,基于时间序列预测了
4.Soar: Rank-based Static Object Allocation
现有的初次放置的分层方案目的是最大化利用快速层内存。
作者希望寻找一种方法最初就能精准放置内存,降低内存迁移开销。

读到这句话的时候这难受。。
挑战:
While AOL-based prediction is effective at the workload level, it falls short for individual objects due to the semantic gap between architectural events and object-level memory accesses.
尽管AOL预测在workload级别能够表现得很好,但是却无法在单个变量上表现很好。
key insight:
distribute CPU stalls across objects proportionally to their relative access frequencies based on the observed MLP and latencies, thereby approximating each object’s performance impact to application performance accurately.
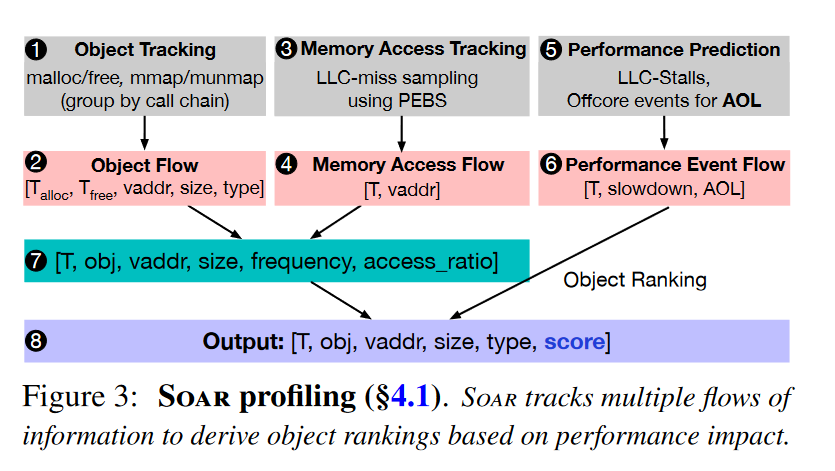
Object-Level Performance Profiling
Periodically collects and processes three types of metrics:
- object metadata via object tracking
- memory accesses via PEBS-based LLC-miss sampling
- temporal performance via AOL-based prediction
- ①-②Object Tracking/Flow 通过
LD_PRELOAD的方式拦截修改,记录五元组对象流 - ③-④用PEBS记录LLC misses、访问时间戳和vaddr
- ⑤-⑥基于AOL预测性能
⑦ 合并三个对象流,基于时间戳来判断地址,有了访问时间戳,可以计算访问次数以及访问比例。
⑧将访存比例与AOL减速预测结合,计算减速得分
具体计算算法:
极端场景下并行少,MLP=1,减速打分等于时间段减速P*访存比例R
高MLP时,缩小评分
低MLP时,放大评分
作者随后解释了怎样设计的factor,以及计算单位字节得分等。

Object Allocation
依然是打分之后进行排序,topk 放置到快速层
影响排名不一定与请求顺序相同,如果打分低的先到了,后续打分高的请求到了会使得打分低的请求降级。
问题:是依据调用栈来进行分组对变量进行标识的,这样在一个函数内部进行内存分配时,大家调用栈都相同,这样并无法区分。
具体要看代码实现是否区分时空调用?
特别指出可以与一些异构内存感知的内存分配器同时使用(memkind、Unified Memory Framework)
Use Cases and Limitations
1.HPC、在线服务这种长时间访问的应用,静态分配不再最优
2.假设对象是均匀的,对象内部的访问每一页频率都差不多。
5.Alto: AOL-based Adaptive Page Migrations
现在方案的不足:
1.某些迁移没有。只是表面热
2.迁移开销很大,策略到单次迁移需要12us,访问到迁移中的页导致CPU stall
3.CXL与local的延迟和带宽都在缩小,迁移开销的影响就显得很大
4.冷页不是真的冷。
虽然用 AOL(Amortized Offcore Latency)来设计基于性能感知的页迁移(page-level migration)策略是很有前景的,但目前仍面临一些独特的挑战,特别是在如何用现有粗粒度硬件性能计数器(performance counters)准确估算单个内存页的性能影响方面。
方法很简单,就是用AOL辅助平时的方法决策一下:
而后讲了与TPP、Nomad、NBT等方法的集成。
6.Evaluation
关注1:CXL模拟方式:SKX lowering the uncore frequency and disabling cores on one NUMA node
关注2:workloads : GAPBS、ML、caching、SPEC2017
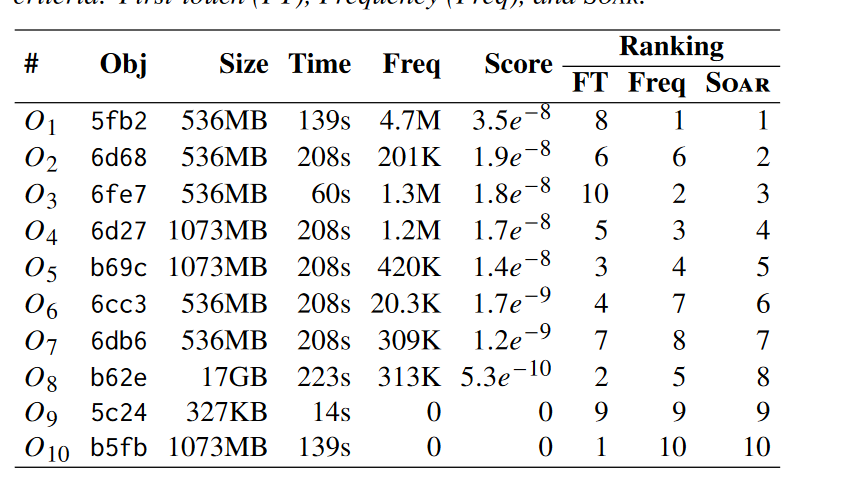

执行过程中的排序
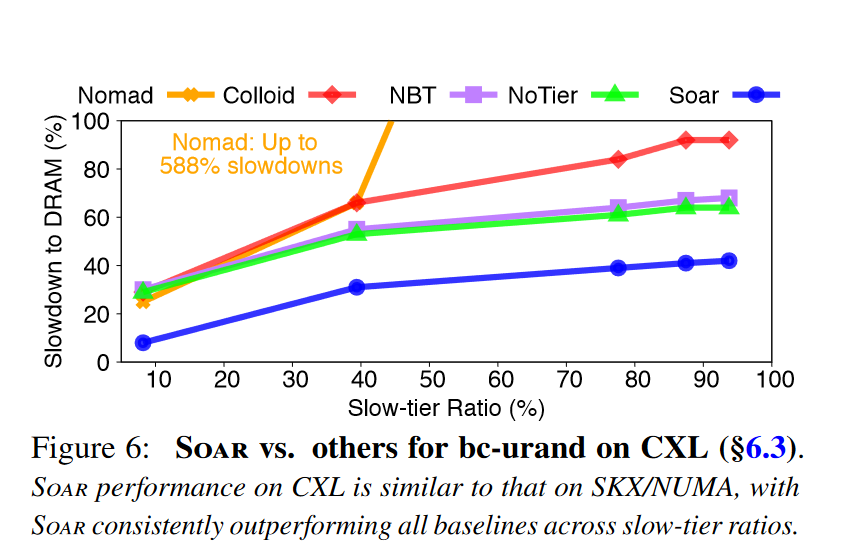
ALTO效果。
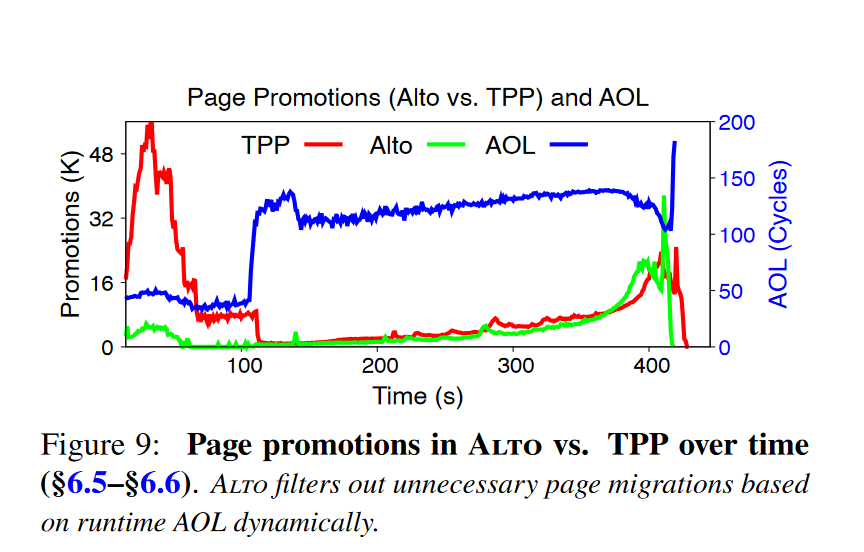
不足与机会:
1.从MLP的角度分析,和预取有关系吗?对于预取的影响(如果这个东西能量化,也能分析出很多东西)
2.并没有考虑区分读写比例的影响?
3.本文中第4节提到的通过访存比例来分配内存slowdown的做法是否合理? 是因为其指标是基于perf stat的,如果全部用perf record的方法是否会更加精确?这一点作者没有详细描述。 hard
4.全部放在运行时进行变量分析会不会发生采样不准确的问题,在NeoMem中也有?但是如何解决?可不可以结合NeoMem完全捕获数据流?
基于采样,长生命周期的可能采集到,短生命周期取样。
机器的拓展性,针对SPX,其他的SPR、EMR的对应事件的拓展性替代如何,是否都只是PEBS?
乱序校正的影响大不大?
例如三段式的,第一次进行热点代码识别,第二次将热点代码全部卸载到CXL,然后利用Neomem捕获trace,从而准确感知,最后根据决策实现数据放置? hard
5.结合内存分配器进行小变量页内集中优化,大变量的访问是否集中?不集中的话可以用perf采集地址,然后绘制访存直方图。



