
背景
PIM和PNM
PIM 的计算单元与存储单元结合紧密,处于内存芯片内部。在传统 PIM 方法里,计算单元被放置在主存储器(DRAM)中,与存储单元在物理上紧密相连。像美光的混合存储立方体(HMC),在 DRAM 层的堆栈下设置逻辑层,期望在逻辑层实现自定义逻辑;
NM 的计算单元在物理上靠近内存阵列,但与 PIM 相比结合程度没那么紧密。其处理单元可部署在不同位置,形成多种架构形态。常见的位置有 3D 堆叠内存的逻辑层,如三星 HBM-PIM 在 HBM2 内存堆栈的每个存储体中集成可编程计算单元(PCU);
PIM内存密度低,容量小;PNM带宽没有优势。
GPU推理特点
带宽在内存不足时会趋近饱和;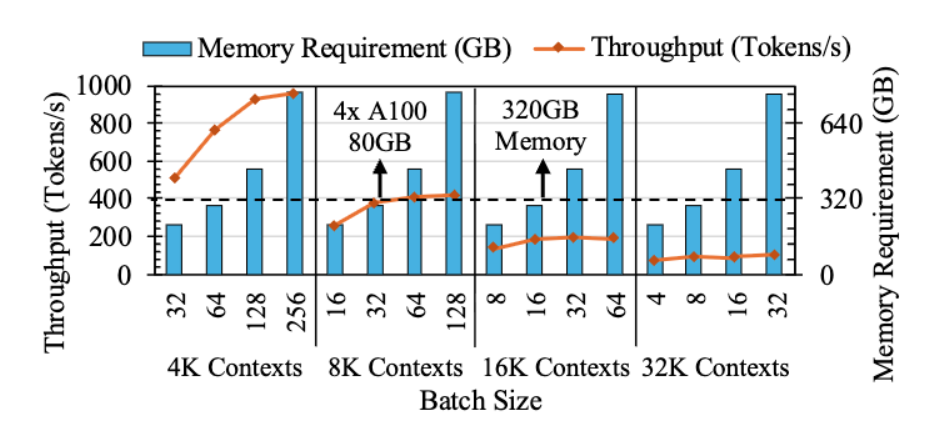
decoder-only与传统大模型相比GPU算力利用率更低
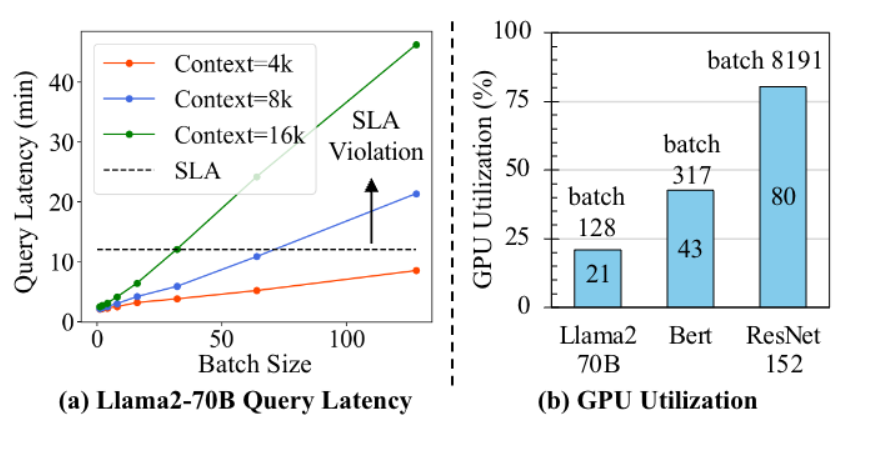
PIM具有极大的内部带宽

PIM具有极低的内存密度
言外之意存储容量不够
为什么需要Hierarchical PIM-PNM架构?
有两种操作:
1.在near-bank使用通用处理PU;2.使用专用的near-bank PUs进行DSA计算,同时在PIM中进行了其他操作。
CENT硬件架构
一个CPU连接了CXL Switch 连接32个CXL device。每个device包含了CXL控制器;每个控制器包含一个PNM和16个chips,每个chips包含了两个PIM。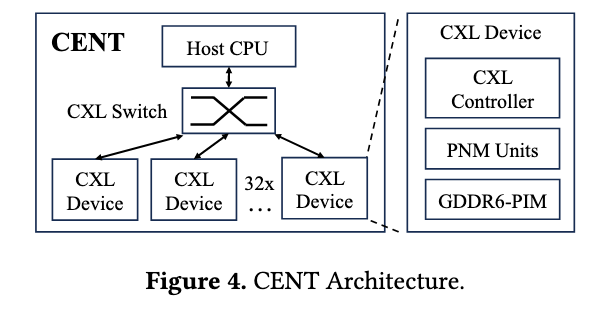
CXL switch支持CPU到CXL通信、以及CXL之间的点对点通信;
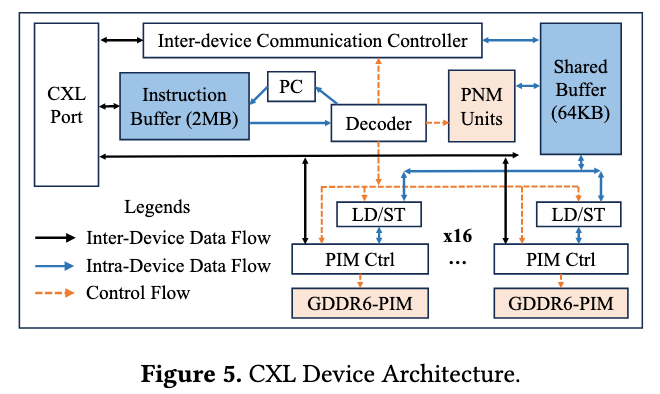
CXL-based Network Architecture
CENT 以CXL 3.0为技术底座,复用 PCIe 6.0 物理层实现高速互连,同时通过协议定制满足 LLM 推理的低延迟与高带宽需求。复用了物理层。CXL于host之间采用x16通道链路,理论带宽128GB/s;CXL于switch之间采用x4通道,理论带宽32GB/s;使用了CXL.io. CXL.mem;未使用CXL,cache;
Inter-Device Communication(设备间)
Figure 5展示了单个 CXL设备的内部结构。CXL设备之间的通信主要使用了IDCC和Shared Buffer
设备之间通信采用了三个通信原语:
SEND_CXL :“非阻塞” 指令,需明确指定目标设备 ID(DVid)、源设备与目标设备的共享缓冲区地址;
RECV_CXL: 与SEND_CXL 相反,RECV_CXL 是 “阻塞式” 指令,且无需指定源设备 ID;
SEND和RECV构成一次完整的CXL写事务;
事务流程:
- 源设备执行 SEND_CXL,将共享缓冲区(Rs)中的数据封装为 CXL 帧(含 DVid、Rd 地址),通过 CXL 端口发送给交换机;
- CXL 交换机解析帧头的 DVid,将数据转发到目标设备的 CXL 端口;
- 目标设备通过 RECV_CXL 监测到端口数据,按 Rd 地址写入本地共享缓冲区,并向源设备返回 “无数据响应(NDR)”;
- 源设备收到 NDR 后,确认数据传输完成(非阻塞指令的 “完成通知”)。
BCAST_CXL :非阻塞指令,通过 8 位 DVcount 参数指定 “需广播数据的后续 CXL 设备数量”。
单个CXL设备通过一个请求写数据到多个设备,基于PBR(基于端口的路由机制)的filt的预留字段实现,设置了一个标记广播位。
有一个确认机制,广播出去以后需要目标设备接收数据并返回NDR后才会执行,避免数据丢失
CXL端口的实现
如图Figure6:主要就是发送队列和接收队列的实现
相应术语:L2R;(local 2 remote).读写事务对应的各种包


Hierarchical PIM-PNM Architecture
如图5.也是一个取指译码的过程,指令先被放到一个指令缓冲区,然后译码器执行并分发到PNM和PIM。(标准的读写事务被直接分发给PIM处理,其他的则转化为微操作分发到PIM和PNM)
PIM
PIM接收微操作然后转化为相关的DRAM指令,Figure 7a 展示每个PIM channel结构。每个bank有32MB容量和一个near-bank PU;
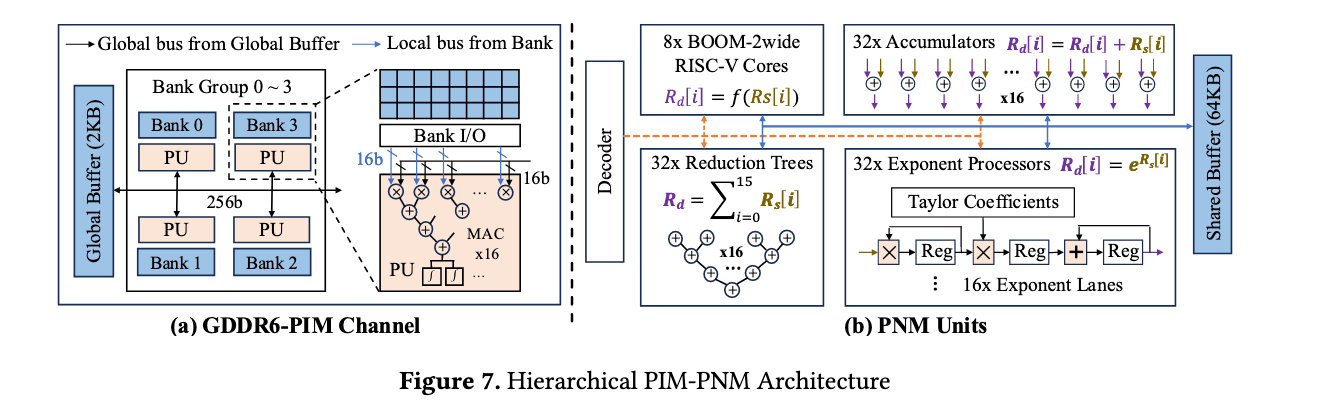
值得注意的是,near-bank中实现了一个16 MAC reduction tree(16路MAC规约树),专门用来做乘加运算。如GEMV,本质是向量元素与矩阵元素做乘法,然后累加求和。接收16组16bit*16bit的输入数据,然后并行执行16次乘法,最后输入一个32bit的累加结果。这些输入来自临近的bank或者是全局的buffer,这一点有点类似CUDA编程。
全局缓冲区可以向通道内不得16个PU共享256bit的数据,实现数据复用,降低内存访问延迟。类似CUDA中的全局内存。每个PU内部有一个32bit的累加寄存器存储MAC 的结果,这个寄存器的结果访问可以由定制的ISA访问。激活函数利用DRAM中的查找表LUT和线性插值实现;避免了复杂的电路。
同时介绍了DRAM于PU的同步,DRAM存储体每2ns向PU输出1次16bit的输入,PU每2ns完成一次16路规约树计算,最大化PIM通道的计算-内存访问overlap;然后介绍了一些通过不同PIMchannel的指令如ACTab等指令。
PNM单元
PNM如Figure7b所示。包含(1).32个累加器,输入从Shared Buffer中取得,执行残差连接等;(2)32个规约树,每一路从shared buffer中获得一个256bit的值(16组BF),执行多元素求和;(3)指数加速器;(4)2发射超标量流水线RISCV核心,执行一些不常见操作;
Intra-Device Communication
设备内部通信,WR_SBK、RD_SBK等实现DRAM banks与Shared buffer 之间的移动;
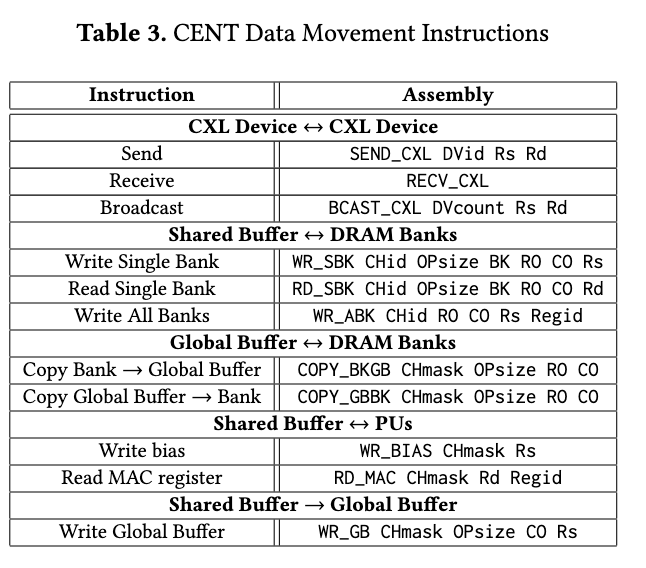
ISA 总结
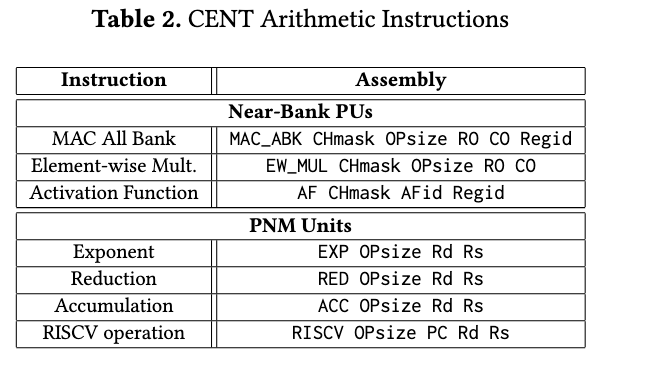
基于这些数据移动指令和部件,实现了一些对外暴露的相关ISA操作,见Table2
模型映射 (软件架构)
大模型高参数以及PIM的低存储密度,所以并行化策略很重要。这一节主要讲如何利用这些硬件,重点是如何利用进行模型并行化。
Pipeline-Parallel Mapping (PP)
云服务器提供商服务数万到数百万用户的查询,吞吐量(单位时间内处理的查询数)至关重要。传统GPU存储因为KV cache占用内存大导致吞吐量难以提升。
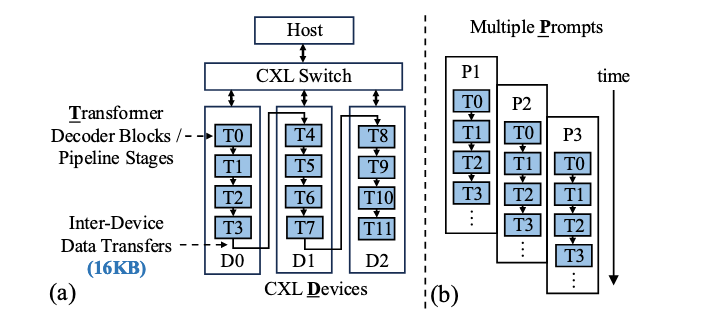
以Transfomer块拆分为流水线阶段。不同查询在流水线的不同阶段同时执行。根据负载均衡进行块在CXL之间的划分依据,避免单个块内的通行,避免拆分流水线放到不同的CXL设备的PIM channels中;
上一个块执行完传到下一个块进行,实现了请求并行,每次传的块是16KB。
受限于Global Buffer的大小,不支持批处理请求(一次请求多个请求);
言外之意流水线并行就是每个CXL设备处理每个请求的一部分,然后放给下一个CXL设备继续处理,但是每次只能处理一个请求,不能同时处理多个请求。
Tensor-Parallel Mapping (TP)
所有资源同时处理一个解码器块,有效降低延迟。
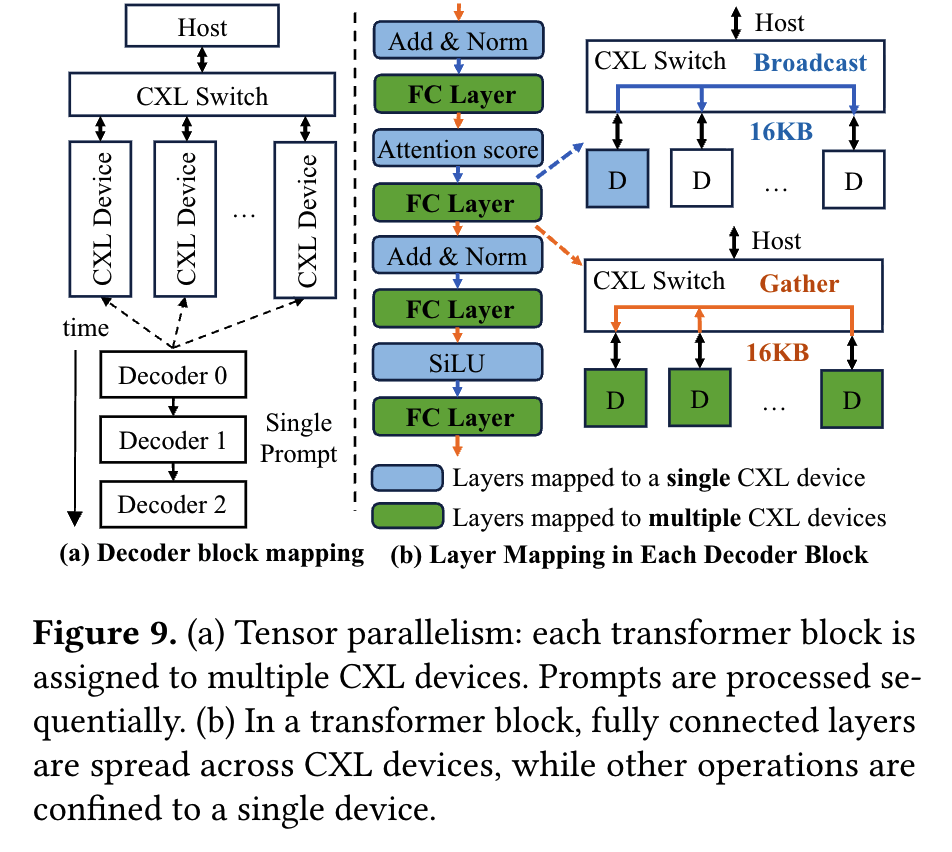
Figure 9展示了分配方案, 具体每个层是放在一个CXL设备还是多个CXL设备是按照通信开销来决定:计算密集且通信少的层拆分并行,通信密集或轻量的层单设备执行。
Hybrid Tensor-Pipeline Parallel Mapping
将每个 Transformer 解码器分配给多个连续的 CXL 设备。例如,在 32 个设备的情况下,将每个解码器映射到 32/4 = 8 个设备上,这样就实现了 TP=8 和 PP=4。其中,张量并行是将单个张量(如权重矩阵)按维度拆分,不同设备计算张量的部分子块,通过通信拼接结果。流水线并行则是将模型按层拆分,不同设备按 “流水线” 顺序执行,前一设备的输出作为后一设备的输入
Transformer Block Mapping
一个层是如何在CXL设备上执行的: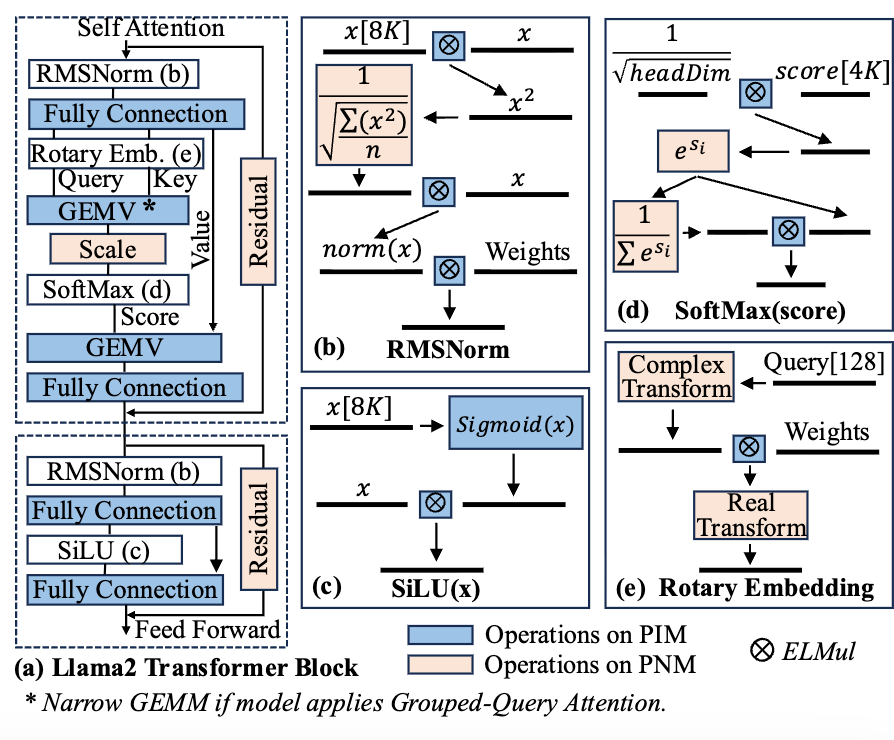
并且详细讲解了GEMV、向量点积、元素级乘法等操作的对应优化。
End-to-End Model Mapping
prefill直接在CXL上按照上述方法映射Transformer,执行后top-k采样在CPU上执行
Programming Model
为了更加简单的使用,又进行了一次封装,只需要配置并行策略等,自研的编译器会进行转换。保证执行的效率。
名义上的编译器,其实就是二次封装,更像是一个算子库,封装了常见的算子。

实验方法论及结果
进行了并行策略对比、GPU与CENT跨平台性能对比、场景适配性测试、敏感性测试
吞吐量提高了,成本降低了,能耗降低了
个人评价
1.PIM没有真实设备实现,但是其硬件结构设计、到ISA到多种并行方式从底层到上层垂直打通,最大优势是利用了PIM的带宽。
2.并行策略丰富,常见的并行策略都有所考虑。
3.实验部分没有仔细看,是采用模拟器模拟执行,CXL采用这种模拟框架在后续实验中也许可以使用。(类似的模拟器方法包括摩尔线程的SimuMax)结合摩尔线程的这个模拟库修改可以实现GPU-CXL协同计算的一些环境模拟,应该可以发掘一些场景,CPU+GPU不行或者全CXL不行,需要GPU+CXL或者CPU+GPU+CXL。有些人可能比较容易想到这样协同的点,但是实现起来很困难,借助这个模拟器可以实现。



