Nvidia/GPU/CUDA相关:
1.描述一下SM的结构,在写kernel的时候共享内存大小和寄存器文件数量需要注意吗?
SM是NVIDIA GPU的核心计算单元,包含
CUDA core,最核心的基本计算单元,处理整形和单精度浮点运算。
寄存器文件、
Warp Scheduler线程数调度器,
共享内存
L1cache
等
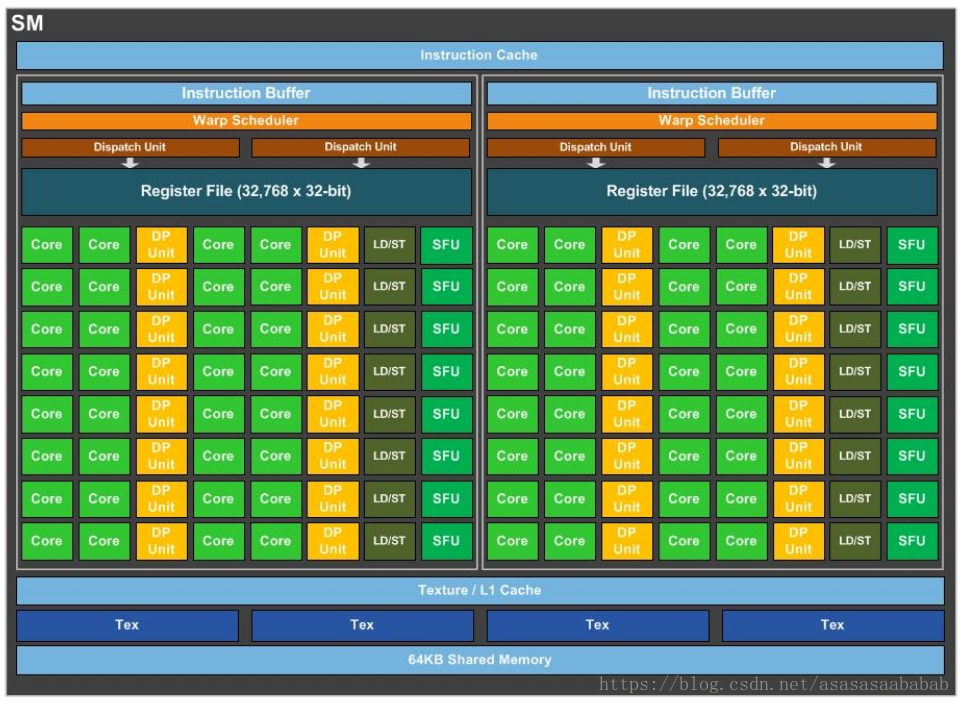
写kernel时共享内存大小和寄存器文件数量直接影响SM的活跃线程束数量(Occupancy)—-即SM上同时可执行的线程束数与最大可支持线程束数的比率。
共享内存大小:
注意:必须注意。共享内存是按块分配的有限资源。
影响:每个块申请的共享内存越大,一个SM上能同时驻留的线程块就越少,会降低占用率(Occupancy),可能影响性能。
寄存器数量:
- 注意:必须注意。寄存器是按线程分配的有限资源。
- 影响:
- 每个线程使用的寄存器越多,一个SM上能同时驻留的线程就越少,同样会降低占用率。
- 寄存器使用过多会导致寄存器溢出(Register Spilling),编译器被迫将变量存储到慢速的全局内存中,严重损害性能。
2.共享内存和寄存器分别应该存放哪些数据,其用量与SM上活跃的线程块的关系。
共享内存
从全局内存预加载的数据块、中间计算结果(如规约运算的局部和)
作用:协作、缓存、通信
寄存器
线程私有的局部数据
作用:私有性、高性能
关系
SM上的活跃线程块数量同时受共享内存总量和寄存器总量的硬性约束,最终的实际数量是以下三个计算结果中的最小值:
- SM支持的最大线程块数(架构限制)。
SM共享内存总量 / 每块申请的共享内存大小。SM寄存器总量 / (每线程寄存器数量 * 每块线程数)。
3.bank冲突是什么?描述具体结构,如何解决?
Bank冲突
为了提供高带宽,共享内存被物理上划分为若干个(通常是32个,与Warp大小对应)同样大小的、能同时被访问的内存模块,这些模块称为 Bank。
理想情况(无冲突): 如果一个Warp中的32个线程分别访问32个不同Bank中的地址(或者访问同一个Bank中的完全相同的一个地址,即广播),那么所有这些访问都可以在一个时钟周期内一次性完成。
冲突情况: 如果一个Warp中的多个线程访问了同一个Bank中的不同地址,就会发生Bank冲突。硬件必须将这些冲突的访问拆分成多个没有冲突的周期依次执行。有
n个线程访问同一个Bank的不同地址,就需要n个时钟周期来完成原本一个周期就能完成的工作。
Bank编号
Bank编号 = (地址字节偏移量 / 4字节) % 32
解决
核心思路是:改变数据在共享内存中的布局或访问模式,确保一个Warp内的线程访问不同的Bank。
方法一:内存填充(Memory Padding)
- 问题: 在操作二维数组(例如矩阵)的Tile时,如果数组的宽度是Bank数量(32)的整数倍,那么同一行中相邻的元素会位于不同的Bank,但同一列中相邻的元素会因为固定的步长而落在同一个Bank里。当线程按列读取时,就会导致严重的Bank冲突。
- 解决方案: 在声明共享内存数组时,人为地给每一行增加一些多余的“填充”元素,使实际的行长(Pitch)不再是32的整数倍。
示例:一个32x32的Tile
cpp
1 | // 可能产生Bank冲突的声明 |
这样,原来在同一列上的元素 tile[0][0], tile[1][0], tile[2][0]… 现在变成了 tile_padded[0][0], tile_padded[1][0], tile_padded[2][0]…。
计算它们的Bank编号:
(0 / 4) % 32 = 0( (1 * 33 * 4) / 4 ) % 32 = (33) % 32 = 1( (2 * 33 * 4) / 4 ) % 32 = (66) % 32 = 2
它们被巧妙地分散到了不同的Bank中,从而避免了冲突。
方法二:改变访问模式或算法
设计核函数时,尽量让一个Warp内的线程访问连续的共享内存地址。因为连续地址通常映射到不同的Bank,这是最友好的访问模式。
方法三:使用不同的广播机制
如果确实需要让多个线程读取同一个值,应尽量确保它们访问的是完全相同的地址,这会触发广播机制,在一个周期内完成操作,而不是产生冲突。
4.说一下分支冲突(线程束分化),如果warp内有冲突,部分符合if条件,部分符合else条件,是否需要等待?
分支冲突发生在同一个Warp内部的线程执行了不同的控制流路径时。例如,部分线程满足if条件,而另一部分线程满足else条件。
- 串行化执行: GPU的Warp调度器会让Warp先执行所有走
if路径的线程。此时,那些本该走else路径的线程在这个阶段是被禁用(masked out) 的,它们不会执行任何操作,但必须等待。 - 再次执行: 当
if路径执行完毕后,调度器会再让Warp执行所有走else路径的线程。同样,此时走if路径的线程被禁用并等待。 - 汇合后继续: 当所有不同的控制流路径都执行完毕后,Warp内的所有线程才会在汇合点(reconvergence point) 重新同步,并继续一起执行后续的相同指令。
因此,分支冲突的性能代价是:执行时间变成了所有不同路径执行时间的总和,而不是其中最长路径的时间。
怎样避免线程束分化
核心思想:同一个Warp内的数据具有相同的特性,从而执行相同的指令路径。
预处理数据,使同一Warp数据特征一致
谓词执行 用条件赋值 ?: 替代短小的 if-else
项目中用过TensorCore吗?了解TensorCore的原理吗?
为什么用float4向量来存取数据?有什么好处?
为什么用双缓冲优化?了解cuda流和cuda graph吗?
除了MPI,有知道现在用的更多的GPU通信库吗?
在Nsight Computing中,经常关注的与内存相关的指标。有关注L1 Cache命中率吗?
GPU指令集优化方面了解吗?有做过PTX相关的优化吗?
GEMM是计算密集型还是访存密集型算子?
知道cutlass中如何对GEMM进行优化的吗?
训练推理
了解Transformer吗?底层是什么结构?cuda中如何优化?
说一下你对大模型的理解。
cuda中如何写Softmax?某个参数过大如何解决?
Dropout和BatchNorm在训练和推理时有什么区别?
说一下你了解的无监督学习算法。
知道Faster Transformer吗?有了解如何实现的吗?
Paged Attention有了解吗?
知道TensorRT吗?部署过推理模型吗?



