第一章 GPU硬件架构与CUDA开发环境配置
1.1 CUDA设备架构详解
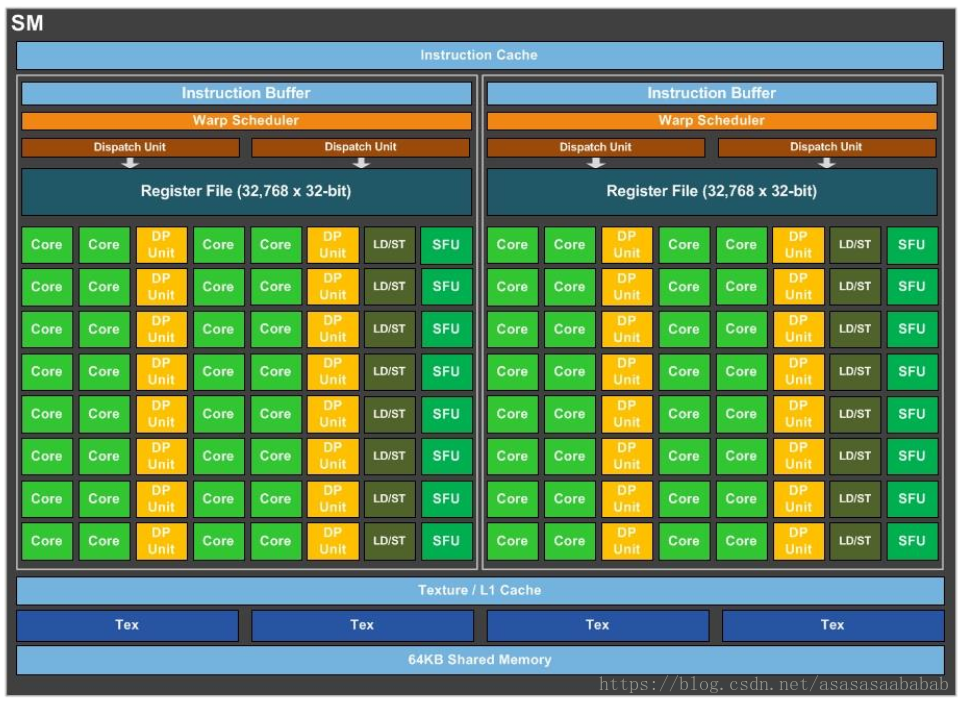
SM是GPU中最基本的计算单元,负责线程调度与数据处理,由多个计算核心CUDAcore和调度单元组成。
GPU中32个线程组成一个warp,是最小的调度单元,SM中的调度器按照Warp执行指令
SM中线程过多会导致寄存器等资源不足,过少计算核心可能会出现空闲现象 如何确定不同架构SM的最适合的线程数呢?
1.Warp是SIMD模式,同一时间执行相同的线程,处理不同的数据。如果出现分支,则会出现线程束分化(发散)的情况:减少分支发散的方法包括:
- 合并分支代码:将条件判断转换为数学式计算
- 调整任务划分,将差异移动到warp之间
- 使用Warp shuffle指令
Warp shuffle基本原理:
Warp shuffe允许同一Warp内线程直接交换寄存器中的数据,无需依赖共享内存;
具有低延迟、无同步、灵活
常见 warp_shaffle指令:
- __shfl_down_sync 将数据从高编号线程传递到低编号线程
- __shfl_up_sync: 将数据从低编号传递到高编号线程
- __shfl_xor_sync:实现交叉线程交换
- __shfl_sync:实现任意线程之间的数据交换寄存器是被线程独占,不和其他线共享,单个线程占用寄存器过多过少都会影响性能,如何优化寄存器的分配策略?
- 优化和函数代码,合并或者复用中间变量,减少寄存器的使用。如避免在循环中多次定义临时变量
- 调整线程块大小,使用nvcc或者是相关的借口查看GPU的线程、寄存器数量支持情况
- 编译器寄存器优化选项,-maxregcount 可以限制每个线程的寄存器数量
如果线程的寄存器需求超过了SM限制,则会溢出到局部内存,局部内存是GPU全局内存的一部分。
1.2 CUDA 运行时与驱动程序
- <cuda.h>和<cuda_runtime.h>,驱动API更复杂和高性能
- nvcc编译步骤:
- 前端处理:分离设备代码和主机代码
- 设备代码编译,转化为中间代码PTX或者二进制代码SASS
- 主机代码编译
- 链接
- nvcc常见编译选项: -O 、-maxregcount、-G、-code、-Xptxas
新手补充
CUDA编程模型与API
devece 设备调用设备
global 主机调用设备
host 主机调用主机
…
第二章 线程与网格组织
很多内容和第一章重复
2.1 CUDA线程模型
- 线程块和SM的关系,受到共享内存、寄存器数量、活动线程数等限制
- 过多过少的线程块都会产生性能影响,最好能利用到所有的SM,又不回导致太多的SM切换线程块
- 线程块大小:决定时考虑内部线程对整个线程块内共享内存和寄存器的分配。
2.2 多维网格与线程索引
2.4 动态并行实现:在核函数中启动新的网络
动态并行原理:
在传统CUDA编程中,核函数只由CPU发起,如果发生进一步任务分解,主机需要再次调度核函数,导致频繁的主机设备通信。
动态并行允许CPU内部核函数启动新的网格,跳过主机参与,实现递归,减少通信开销。
第三章 内存层次
读到此处,感觉这本书大多聚焦在讲XX和XX之间的全很,并没有很清楚的讲清楚结构,一些具体的前置知识也有所遗漏。
个人觉的内存层次这个东西应该参考CPU内存那一套,分别从硬件和软件编程的角度讲清楚。
硬件角度:物理位置、容量、速度
寄存器: SM内
共享内存: SM内
L1/常量缓存/纹理缓存 : 在SM内
L2缓存: SM之间共享
全局内存: 板载DRAM
常量内存: 板载DRAM
局部内存: 板载DRAM
软件角度:编程模型,透明性
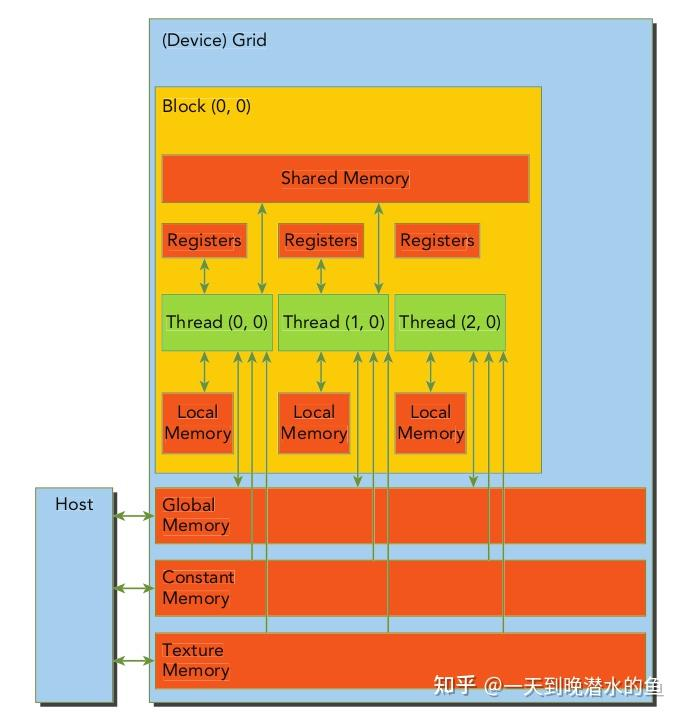
软件角度参考这张图: