GGML 源码浅析(1) 前言 1.阅读路线
1.内存管理:不使用后端时(参见example/simple-ctx)介绍ggml中的重要数据结构以及内存管理
2.后端的设计逻辑
3.基于gpt-2学习模型构建过程中权重与kv-cache管理
2.重点
1.关于ggml-context的相关数据结构,需要理解ggml-contxt中内存分配结构,可以参看其中给的几张图
2.通过输出结果反推构建计算图
3.后端设计中,一定用面向对象的方式来思考相关后端实现,其实就是用c实现了C++的面向对象,自己实现了虚函数表,私有成员变量(void*)
4.一次操作的逻辑
大佬教程 深入理解GGML(一)模型和计算图 - 知乎
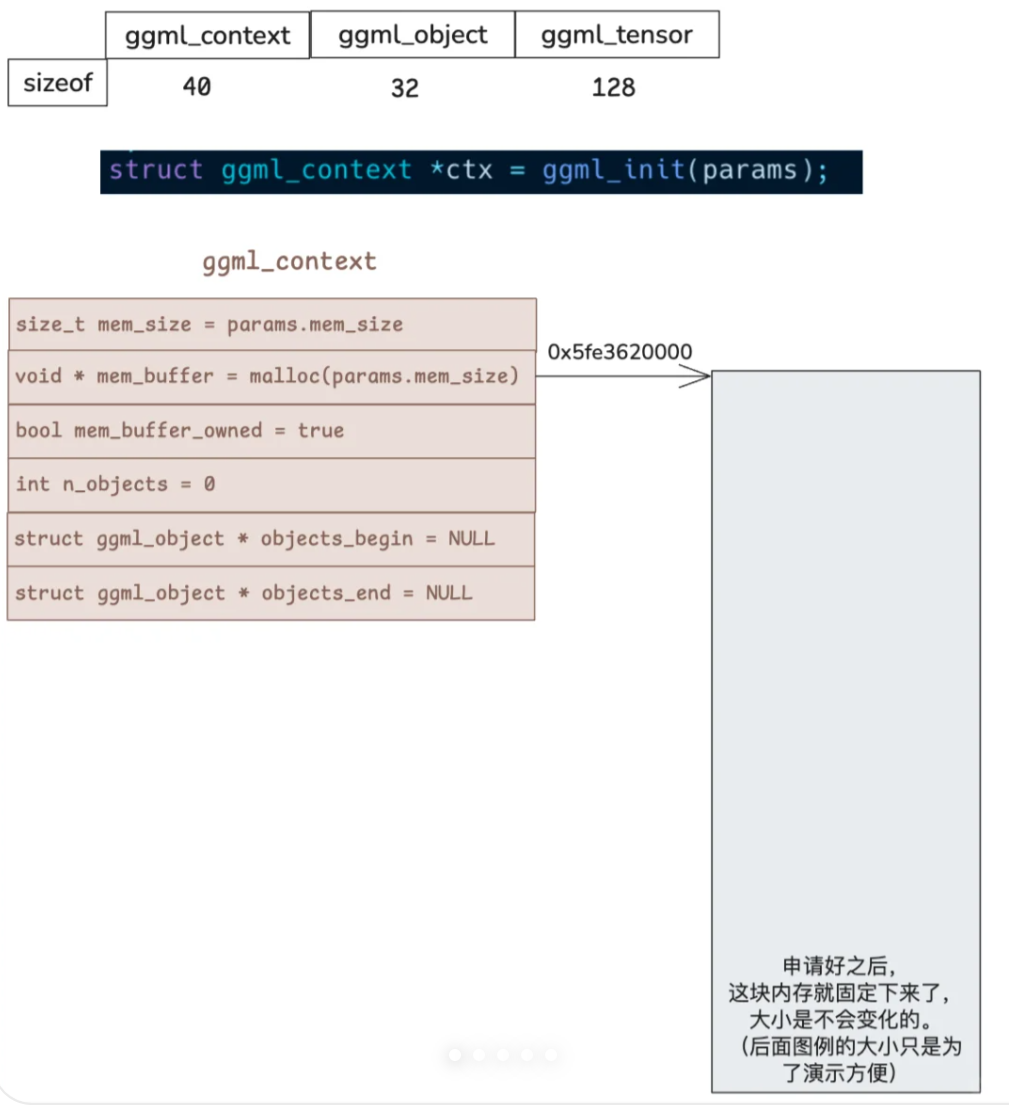
1.核心数据结构 1.1ggml_context 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 struct ggml_context { size_t mem_size; void * mem_buffer; bool mem_buffer_owned; bool no_alloc; bool no_alloc_save; int n_objects; struct ggml_object * objects_begin ; struct ggml_object * objects_end ; struct ggml_scratch scratch ; struct ggml_scratch scratch_save ; }; struct ggml_object { size_t offs; size_t size; struct ggml_object * next ; enum ggml_object_type type ; char padding[4 ]; };
ggml_context是最核心的数据结构,所有的张量、计算图都依赖于这个数据结构:
mem_size表示ggml_init时分配一块多大的内存,后续的张量都从这块内存中分配空间,避免反复的malloc
mem_buffer_owned表示这个mem_buffer是外部传进来的还是自己分配的,决定分配权,避免误释放 。
no_malloc是表示张量分配内存的时候是真的分配内存还是仅仅用于占位
no_alloc_save使用了scratch会强制开启内存,所以需要暂存一下no_malloc
scratch是一块临时内存,用于存放中间的临时结果、缓存
scratch_save暂存scatch的状态
n_objects以及两个指针维护了一个对象双向链表,记录所有已创建的对象,可以看到这个ggml_object主要维护了偏移offs和size,容易理解实际数据就是分配在ggml_context的buffer中,而要找到这些数据就通过object链表来进行查找与分配。
ggml_object这个结构体本本身也是分配在ggml_context.mem_buffer上的,之后跟着对应的数据。
ggml-object->ggml_tensor->tensor_data
这一部分的实现具体查看ggml_new_object
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 static struct ggml_object * ggml_new_object (struct ggml_context * ctx, enum ggml_object_type type, size_t size) { struct ggml_object * obj_cur = const size_t cur_offs = obj_cur == NULL ? 0 : obj_cur->offs; const size_t cur_size = obj_cur == NULL ? 0 : obj_cur->size; const size_t cur_end = cur_offs + cur_size; size_t size_needed = GGML_PAD(size, GGML_MEM_ALIGN); char * const mem_buffer = ctx->mem_buffer; struct ggml_object * const obj_new =struct ggml_object *)(mem_buffer + cur_end); if (cur_end + size_needed + GGML_OBJECT_SIZE > ctx->mem_size) { GGML_PRINT("%s: not enough space in the context's memory pool (needed %zu, available %zu)\n" , __func__, cur_end + size_needed, ctx->mem_size); assert(false ); return NULL ; } *obj_new = (struct ggml_object) { .offs = cur_end + GGML_OBJECT_SIZE, .size = size_needed, .next = NULL , .type = type, }; GGML_ASSERT_ALIGNED(mem_buffer + obj_new->offs); if (obj_cur != NULL ) { obj_cur->next = obj_new; } else { ctx->objects_begin = obj_new; } ctx->objects_end = obj_new; return obj_new; }
实际使用 过程中,可以看到所有的操作都挂靠到ggml_context上
内存分配:
1 2 3 4 5 6 struct ggml_init_params params = .mem_size = 64 * 1024 * 1024 , .mem_buffer = malloc (mem_size), .no_alloc = false }; struct ggml_context * ctx =
张量分配:
1 struct ggml_tensor * a =10 );
可以查看ggml.c/ggml_new_tensor_impl()具体实现,最终分配的tensor的data,指针指向的数据还是ggml_contxt.mem_buf中的对应偏移量。
计算操作:
1 struct ggml_tensor * c =
执行计算图:
1 2 struct ggml_cgraph graph =ggml_graph_compute_with_ctx(ctx, &graph, n_threads);
下边小红书博主**TransormerX **绘制的这几张图 清晰 美观 的展示了内存分配情况:
除了图中绘制的tensor是按照这样的内存分布以外,其他类型graph、workbuffer等类型的object都是采用这样的内存排布,即:object结构体->对应类型结构体(tensor\graph)->相应data
比如图的存储就是object->ggml_cgraph(结构体本身)->节点叶子等指针数组
WORK_BUFFER就是object–>work_data (直接被cplan中的指针所指)
1.2ggml_state 整个ggml程序运行过程中有一个全局的g_state.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 static struct ggml_state g_state ;#define GGML_MAX_CONTEXTS 64 struct ggml_state { struct ggml_context_container contexts [GGML_MAX_CONTEXTS ]; struct ggml_numa_nodes numa ; }; struct ggml_context_container { bool used; struct ggml_context context ; }; struct ggml_numa_nodes { enum ggml_numa_strategy numa_strategy ; struct ggml_numa_node nodes [GGML_NUMA_MAX_NODES ]; uint32_t n_nodes; uint32_t total_cpus; uint32_t current_node; #if defined(__gnu_linux__) cpu_set_t cpuset; #else uint32_t cpuset; #endif };
ggml_state中包含了一个ggml_context(额外加一个used标识而已)数组。
在第一次调用ggml_init时,会对g_state进行初始化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if (is_first_call) { g_state = (struct ggml_state) { { { 0 } }, { .n_nodes = 0 , .total_cpus = 0 , }, }; for (int i = 0 ; i < GGML_MAX_CONTEXTS; ++i) { g_state.contexts[i].used = false ; } }
于是可以理解到,程序运行时,会在全局静态内存区分配一个g_state,包含了一个g_context数组,每次ggml_init的时候就去g_state中找一个没有使用的g_context,获得其指针后进行每个字段的初始化以及填充,之后就依靠这个ggml_context进行一次一次。
目前个人看代码觉得每次模型执行只需要一个ggml_conterxt,但是给了一个64个ggml_context组成的数组,是因为可能需要支持模型的并行(这个观点参考GPT)
1.3ggml_tensor 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 struct ggml_tensor { enum ggml_type type ; GGML_DEPRECATED(enum ggml_backend_type backend, "use the buffer type to find the storage location of the tensor" ); struct ggml_backend_buffer * buffer ; int64_t ne[GGML_MAX_DIMS]; size_t nb[GGML_MAX_DIMS]; enum ggml_op op ; int32_t op_params[GGML_MAX_OP_PARAMS / sizeof (int32_t )]; int32_t flags; struct ggml_tensor * grad ; struct ggml_tensor * src [GGML_MAX_SRC ]; struct ggml_tensor * view_src ; size_t view_offs; void * data; char name[GGML_MAX_NAME]; void * extra; };
这里有一个比较重要的概念是view,view不会信分配内存。一个简单的例子:如果一个短向量是一个长向量的子向量,可以理解为短向量是长向量的子向量,也就是长向量的视图,分配短向量时,可以利用长向量已经分配的内存,从而避免了内存的分配。
1.4 ggml_cgraph 1 2 3 4 5 6 7 8 9 10 11 12 13 struct ggml_cgraph { int size; int n_nodes; int n_leafs; struct ggml_tensor ** nodes ; struct ggml_tensor ** grads ; struct ggml_tensor ** leafs ; struct ggml_hash_set visited_hash_set ; enum ggml_cgraph_eval_order order ; };
2.核心操作 2.1模型加载 gguf结构与解析 gguf定义了模型的权重保存方式,以下为gguf的结构
主要可以分为以下4部分:
1.header 包含模式,tensor数量、kv元数据数、版本等
2.模型元数据(KV表示)
3.每个tensor的信息(offset等,不包含tensor的值)
4.tensor的值
文件ggml.c中,定义了gguf相关的结构体,其中gguf_context对应于一个文件,包含header、kv、tensor_info等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 union gguf_value { uint8_t uint8; int8_t int8; uint16_t uint16; int16_t int16; uint32_t uint32; int32_t int32; float float32; uint64_t uint64; int64_t int64; double float64; bool bool_; struct gguf_str str ; struct { enum gguf_type type ; uint64_t n; void * data; } arr; }; struct gguf_kv { struct gguf_str key ; enum gguf_type type ; union gguf_value value ; }; struct gguf_header { char magic[4 ]; uint32_t version; uint64_t n_tensors; uint64_t n_kv; }; struct gguf_tensor_info { struct gguf_str name ; uint32_t n_dims; uint64_t ne[GGML_MAX_DIMS]; enum ggml_type type ; uint64_t offset; const void * data; size_t size; }; struct gguf_context { struct gguf_header header ; struct gguf_kv * kv ; struct gguf_tensor_info * infos ; size_t alignment; size_t offset; size_t size; void * data; };
ggml.c/gguf_init_from_file实现了从文件加载模型到结构体中
2.2计算图(前向图)构建 以simple-ctx为例说明计算图构建流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 struct ggml_cgraph * build_graph (const simple_model& model) { struct ggml_cgraph * gf = struct ggml_tensor * result = ggml_build_forward_expand(gf, result); return gf; } struct ggml_tensor * ggml_mul_mat ( struct ggml_context * ctx, struct ggml_tensor * a, struct ggml_tensor * b) { GGML_ASSERT(ggml_can_mul_mat(a, b)); GGML_ASSERT(!ggml_is_transposed(a)); bool is_node = false ; if (a->grad || b->grad) { is_node = true ; } const int64_t ne[4 ] = { a->ne[1 ], b->ne[1 ], b->ne[2 ], b->ne[3 ] }; struct ggml_tensor * result =4 , ne); result->op = GGML_OP_MUL_MAT; result->grad = is_node ? ggml_dup_tensor(ctx, result) : NULL ; result->src[0 ] = a; result->src[1 ] = b; return result; }
ggml_new_graph会在ggml-contxt中相关的内存区域分配ggml_cgraph的内存,进行初始化;
而后进行实际的算子构建,这个过程每一步得到的输出张量会记录对应的输入、以及操作类型,参照上边的ggml_tensor的数据结构
最后核心的函数是ggml_build_forward_expand,这个过程根据输出的tensor,反向添加graph中的计算节点。
即流程为手动设置最终输出tensor的过程,利用tensor中的变量反向构建静态输出图,成功在graph中添加不同的节点,完成graph的维护
具体构建过程见:ggml.c/ggml_visit_parents简言之就是后序遍历+hash去重,填充cgraph中的相关指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 static void ggml_visit_parents (struct ggml_cgraph * cgraph, struct ggml_tensor * node) if (node->grad == NULL ) { if (node->op != GGML_OP_NONE) { } } if (ggml_hash_insert (&cgraph->visited_hash_set, node) == GGML_HASHSET_ALREADY_EXISTS) { return ; } for (int i = 0 ; i < GGML_MAX_SRC; ++i) { const int k = (cgraph->order == GGML_CGRAPH_EVAL_ORDER_LEFT_TO_RIGHT) ? i : (cgraph->order == GGML_CGRAPH_EVAL_ORDER_RIGHT_TO_LEFT) ? (GGML_MAX_SRC-1 -i) : i; if (node->src[k]) { ggml_visit_parents (cgraph, node->src[k]); } } if (node->op == GGML_OP_NONE && node->grad == NULL ) { GGML_ASSERT (cgraph->n_leafs < cgraph->size); if (strlen (node->name) == 0 ) { ggml_format_name (node, "leaf_%d" , cgraph->n_leafs); } cgraph->leafs[cgraph->n_leafs] = node; cgraph->n_leafs++; } else { GGML_ASSERT (cgraph->n_nodes < cgraph->size); if (strlen (node->name) == 0 ) { ggml_format_name (node, "node_%d" , cgraph->n_nodes); } cgraph->nodes[cgraph->n_nodes] = node; if (cgraph->grads) { cgraph->grads[cgraph->n_nodes] = node->grad; } cgraph->n_nodes++; } }
后向图的构建过程更加复杂一些,会同时保存相关的梯度信息。
后向图的构建依赖前向图,后向图靠拷贝了前向计算图,
2.3计算 核心函数
1 2 3 4 5 6 7 8 9 enum ggml_status ggml_graph_compute_with_ctx (struct ggml_context * ctx, struct ggml_cgraph * cgraph, int n_threads) { struct ggml_cplan cplan =NULL ); struct ggml_object * obj = cplan.work_data = (uint8_t *)ctx->mem_buffer + obj->offs; return ggml_graph_compute(cgraph, &cplan); }
主要步骤为,
1.构建执行计划ggml_graph_plan,生成执行顺序和任务计划、所有算子中的预计分配内存大小、线程数量。线程分配数量由ggml_get_n_tasks中的一个switch case决定。其中有一段work_size += CACHE_LINE_SIZE * n_threads;的代码是避免多个线程访问同一个缓存和,造成伪共享。一些可以被多线程执行的算子计算预计内存分配的时候还会乘以线程数,保证不会导致额外的内存同步开销。
2.ggml_new_object生成任务缓冲区,ggml_context中 。
3.执行计算图ggml_graph_compute
ggml_graph_compute
执行ggml_graph_compute时,首先初始化或者设置ggml_threadpool中的相关参数,包括cplan等
只有调用ggml_graph_compute_thread进行多线程处理,启用omp进行多线程处理,否则单线程
其中遍历cgraph中的每个算子节点,通过ggml_compute_forward转发到不同的算子进行计算,每个算子内部区分不同的精读,转发到不同的精度处理函数,最后不同的精度计算算子函数 通过ith\nth考虑线程分配,内存存取
将线程划分计算的权利交给了算子自身来执行。
例如以f16_add为例,通过ith划分举证的行和列,每个线程计算不同的小矩阵,实现并行化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 static void ggml_compute_forward_add_f16_f16 ( const struct ggml_compute_params * params, struct ggml_tensor * dst) { const struct ggml_tensor * src0 =0 ]; const struct ggml_tensor * src1 =1 ]; GGML_ASSERT(ggml_are_same_shape(src0, src1) && ggml_are_same_shape(src0, dst)); const int ith = params->ith; const int nth = params->nth; const int nr = ggml_nrows(src0); GGML_TENSOR_BINARY_OP_LOCALS GGML_ASSERT (src0->type == GGML_TYPE_F16) ; GGML_ASSERT(src1->type == GGML_TYPE_F16); GGML_ASSERT(dst->type == GGML_TYPE_F16); GGML_ASSERT( nb0 == sizeof (ggml_fp16_t )); GGML_ASSERT(nb00 == sizeof (ggml_fp16_t )); const int dr = (nr + nth - 1 )/nth; const int ir0 = dr*ith; const int ir1 = MIN(ir0 + dr, nr); if (nb10 == sizeof (ggml_fp16_t )) { for (int ir = ir0; ir < ir1; ++ir) { const int i3 = ir/(ne2*ne1); const int i2 = (ir - i3*ne2*ne1)/ne1; const int i1 = (ir - i3*ne2*ne1 - i2*ne1); ggml_fp16_t * dst_ptr = (ggml_fp16_t *) ((char *) dst->data + i3*nb3 + i2*nb2 + i1*nb1); ggml_fp16_t * src0_ptr = (ggml_fp16_t *) ((char *) src0->data + i3*nb03 + i2*nb02 + i1*nb01); ggml_fp16_t * src1_ptr = (ggml_fp16_t *) ((char *) src1->data + i3*nb13 + i2*nb12 + i1*nb11); for (int i = 0 ; i < ne0; i++) { dst_ptr[i] = GGML_FP32_TO_FP16(GGML_FP16_TO_FP32(src0_ptr[i]) + GGML_FP16_TO_FP32(src1_ptr[i])); } } } else { GGML_ABORT("fatal error" ); } }
3.后端实现 快速入门技巧: 用面向对象思想来阅读!
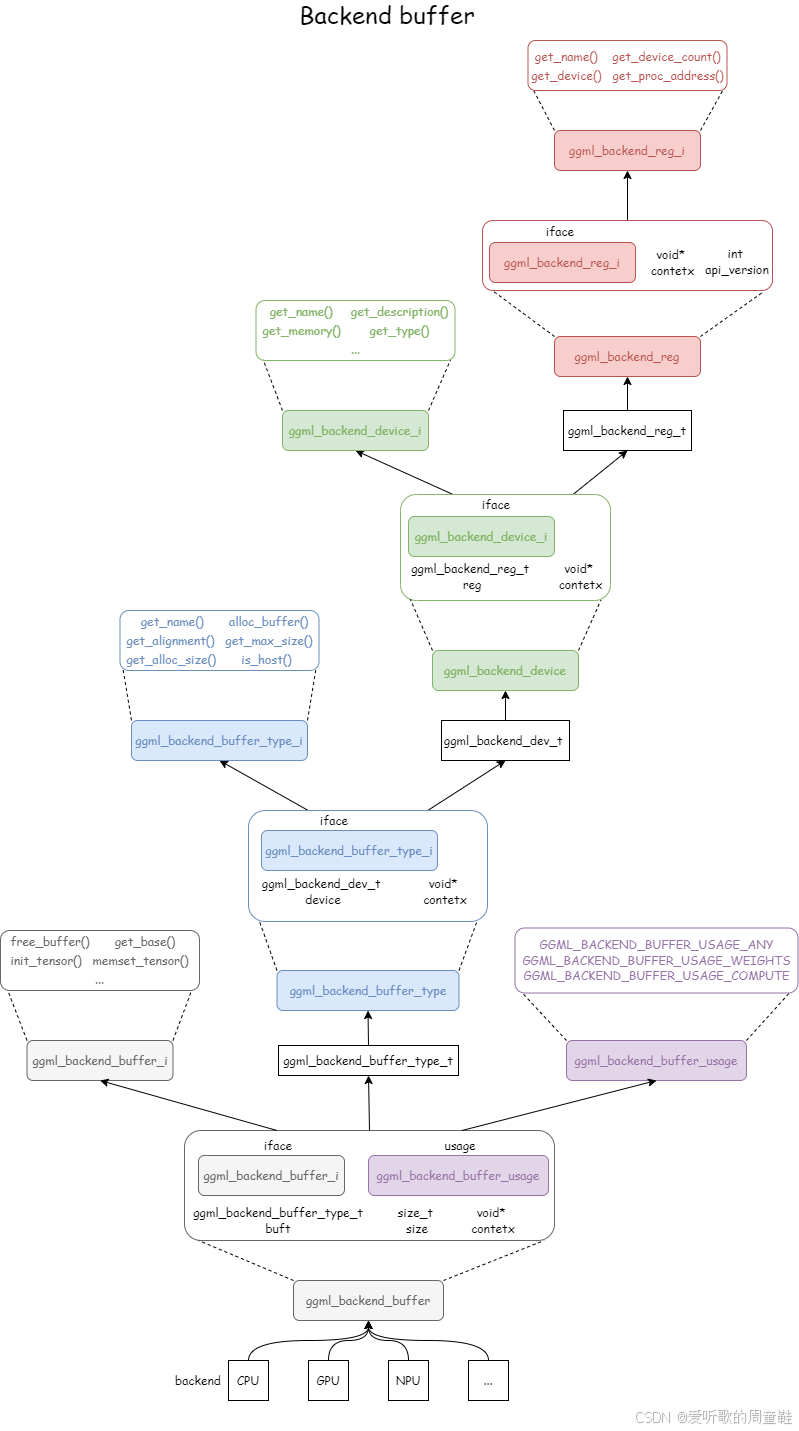
3.1相关数据结构 ggml_backend 查看example/simple代码时,后端的模型中增加了一个ggml_backend结构。
ggml_backend可以理解为一个设备管理器
1 2 3 4 5 6 struct ggml_backend { ggml_guid_t guid; struct ggml_backend_i iface ; ggml_backend_context_t context; };
ggml_backend_buffer 1 2 3 4 5 6 7 struct ggml_backend_buffer { struct ggml_backend_buffer_i iface ; ggml_backend_buffer_type_t buft; ggml_backend_buffer_context_t context; size_t size; enum ggml_backend_buffer_usage usage ; };
又包含了ggml_backend_buffer_type
1 2 3 4 struct ggml_backend_buffer_type { struct ggml_backend_buffer_type_i iface ; ggml_backend_buffer_type_context_t context; };
这里结构体比较多,看起来比较复杂,用这篇博客 中的图片描述是这样的
但是如果用面向对象的思想来理解,一切都很简单。
最开始的初衷是有一个后端基类,不同类型的后端基于此派生,而后端包含有不同的buffer,因此创建了后端buffer一组基类,并作为后端基类的成员变量,相同的方式有了后端buffer-type类
不同的后端有不同的成员变量,也就是ctx,通过void*实现
3.2CPU后端示例讲解 load model 加载模型之前先根据不同的宏启用不同的后端初始化函数,
之后创建对应的ggml_contxt,
创建向量时,首先会将向量存储在CPU,
之后通过ggml_backend_alloc_ctx_tensors
创建对应的后端buffer,然后通过ggml_backend_tensor_set将向量从CPU内存搬到后端内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 void load_model (simple_model & model, float * a, float * b, int rows_A, int cols_A, int rows_B, int cols_B) { #ifdef GGML_USE_CUDA fprintf (stderr , "%s: using CUDA backend\n" , __func__); model.backend = ggml_backend_cuda_init(0 ); if (!model.backend) { fprintf (stderr , "%s: ggml_backend_cuda_init() failed\n" , __func__); } #endif #ifdef GGML_USE_METAL fprintf (stderr , "%s: using Metal backend\n" , __func__); ggml_backend_metal_log_set_callback(ggml_log_callback_default, nullptr); model.backend = ggml_backend_metal_init(); if (!model.backend) { fprintf (stderr , "%s: ggml_backend_metal_init() failed\n" , __func__); } #endif if (!model.backend) { model.backend = ggml_backend_cpu_init(); } int num_tensors = 2 ; struct ggml_init_params params { ggml_tensor_overhead() * num_tensors, NULL , true , }; model.ctx = ggml_init(params); model.a = ggml_new_tensor_2d(model.ctx, GGML_TYPE_F32, cols_A, rows_A); model.b = ggml_new_tensor_2d(model.ctx, GGML_TYPE_F32, cols_B, rows_B); model.buffer = ggml_backend_alloc_ctx_tensors(model.ctx, model.backend); ggml_backend_tensor_set(model.a, a, 0 , ggml_nbytes(model.a)); ggml_backend_tensor_set(model.b, b, 0 , ggml_nbytes(model.b)); }
ggml_backend_cpu_init
ggml_backend_cpu_init XXX_backend_cpu_init负责创建对应的ggml_backend_t结构体
可以看到结构体中的ctx是每个后端有一个自己的结构体
虚函数表interface是全局定义了每个后端的表,如cpu_backend_i
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 ggml_backend_t ggml_backend_cpu_init (void ) { struct ggml_backend_cpu_context * ctx =malloc (sizeof (struct ggml_backend_cpu_context)); if (ctx == NULL ) { return NULL ; } ctx->n_threads = GGML_DEFAULT_N_THREADS; ctx->threadpool = NULL ; ctx->work_data = NULL ; ctx->work_size = 0 ; ctx->abort_callback = NULL ; ctx->abort_callback_data = NULL ; ggml_backend_t cpu_backend = malloc (sizeof (struct ggml_backend)); if (cpu_backend == NULL ) { free (ctx); return NULL ; } *cpu_backend = (struct ggml_backend) { ggml_backend_cpu_guid(), cpu_backend_i, ctx }; return cpu_backend; } static struct ggml_backend_i cpu_backend_i = ggml_backend_cpu_name, ggml_backend_cpu_free, ggml_backend_cpu_get_default_buffer_type, NULL , NULL , NULL , NULL , ggml_backend_cpu_graph_plan_create, ggml_backend_cpu_graph_plan_free, NULL , ggml_backend_cpu_graph_plan_compute, ggml_backend_cpu_graph_compute, ggml_backend_cpu_supports_op, ggml_backend_cpu_supports_buft, NULL , NULL , NULL , NULL , NULL , NULL , };
ggml_backend_alloc_ctx_tensors
核心代码alloc_tensor_range本质就是构造函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 ggml_backend_buffer_t ggml_backend_alloc_ctx_tensors (struct ggml_context * ctx, ggml_backend_t backend) { return ggml_backend_alloc_ctx_tensors_from_buft(ctx, ggml_backend_get_default_buffer_type(backend)); } ggml_backend_buffer_t ggml_backend_alloc_ctx_tensors_from_buft (struct ggml_context * ctx, ggml_backend_buffer_type_t buft) { GGML_ASSERT(ggml_get_no_alloc(ctx) == true ); size_t alignment = ggml_backend_buft_get_alignment(buft); size_t max_size = ggml_backend_buft_get_max_size(buft); ggml_backend_buffer_t * buffers = NULL ; size_t n_buffers = 0 ; size_t cur_buf_size = 0 ; struct ggml_tensor * first = for (struct ggml_tensor * t = first; t != NULL ; t = ggml_get_next_tensor(ctx, t)) { size_t this_size = 0 ; if (t->data == NULL && t->view_src == NULL ) { this_size = GGML_PAD(ggml_backend_buft_get_alloc_size(buft, t), alignment); } if (this_size > max_size) { fprintf (stderr , "%s: tensor %s is too large to fit in a %s buffer (tensor size: %zu, max buffer size: %zu)\n" , __func__, t->name, ggml_backend_buft_name(buft), this_size, max_size); for (size_t i = 0 ; i < n_buffers; i++) { ggml_backend_buffer_free(buffers[i]); } free (buffers); return NULL ; } if ((cur_buf_size + this_size) > max_size) { if (!alloc_tensor_range(ctx, first, t, buft, cur_buf_size, &buffers, &n_buffers)) { return NULL ; } first = t; cur_buf_size = this_size; } else { cur_buf_size += this_size; } } if (cur_buf_size > 0 ) { if (!alloc_tensor_range(ctx, first, NULL , buft, cur_buf_size, &buffers, &n_buffers)) { return NULL ; } } if (n_buffers == 0 ) { #ifndef NDEBUG fprintf (stderr , "%s: all tensors in the context are already allocated\n" , __func__); #endif return NULL ; } ggml_backend_buffer_t buffer; if (n_buffers == 1 ) { buffer = buffers[0 ]; } else { buffer = ggml_backend_multi_buffer_alloc_buffer(buffers, n_buffers); } free (buffers); return buffer; }
总结 1.ggml中分明很多地方都是面向对象的思想写的,但是为什么会用C语言写呢?
更加稳定的ABI,不和编译器强相关
零依赖,轻量化
没有运行时,手动控制内存更方便